スピード テスト¶
2つの行列の積の計算速度をさまざまな方法で比較してみました。
計算速度(GFLOPS)¶
FLOPS(Floating-point Operations Per Second)は1秒間に浮動小数点演算が何回できるかの指標で、1GFLOPSは1秒間に 1000 * 1000 * 1000 = 10億回の計算をします。
2つのN行N列の行列の積 \(C = A \cdot B\) を計算した場合のGFLOPSを考えます。
結果の行列CもN行N列の行列になります。
Cの i 行 j 列の要素は以下のようにN回の乗算と加算をします。
結局Cの計算には N * N * N 回の計算が必要です。
(ふつう加算は乗算よりずっと速いので加算の計算回数は無視します。)
1秒間に行列の積がM回できたとすると計算速度(GFLOPS)は以下の式になります。
テスト環境¶
以下のPCを使いました。
- OS
- Windows10 64bit
- CPU
- Core i7-6700 3.4GHz メモリ:8GB キャッシュメモリ:8MB 論理コア:8個
- GPU
- GeForce GTX 1070 1.5GHz メモリ:8GB CUDAコア:1920個
計算方法¶
5種類の計算方法でテストしました。
以降のグラフの凡例に表示される言葉の意味は以下のとおりです。
- JavaScript
- WebGLを使わずJavaScriptだけで計算しました。
- gpgpu.js
- テクスチャを使った行列の積 で説明した方法です。
- 高速化
- 行列の積の高速化 で説明した方法です。
- C++
- OpenMPを使って並列処理をしました。
- CUDA
- 元祖GPGPU。 NVIDIAのGPUで使えます。
行列サイズ200までのグラフ¶
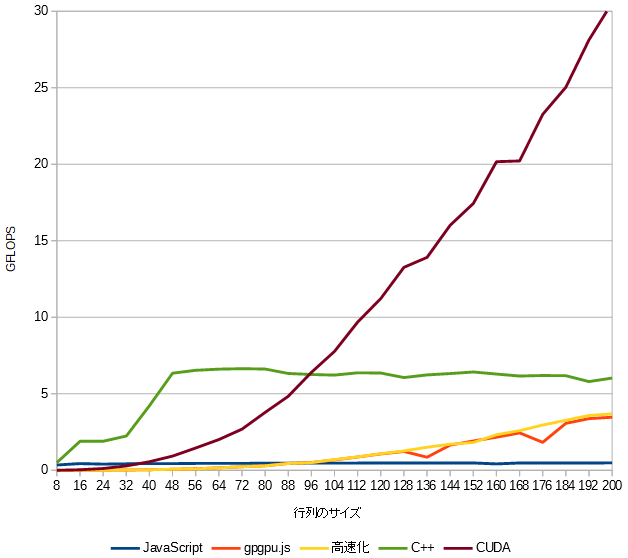
8x8から200x200までのサイズの行列の積の計算速度(GFLOPS)をプロットしました。
このグラフを見ると行列サイズが96以降でCUDAは最速ですが、行列サイズが36以下だとJavaScriptよりも遅いです。
gpgpu.jsは行列サイズが90ぐらいからJavaScriptよりも速くなっています。
行列サイズ2000までのグラフ¶
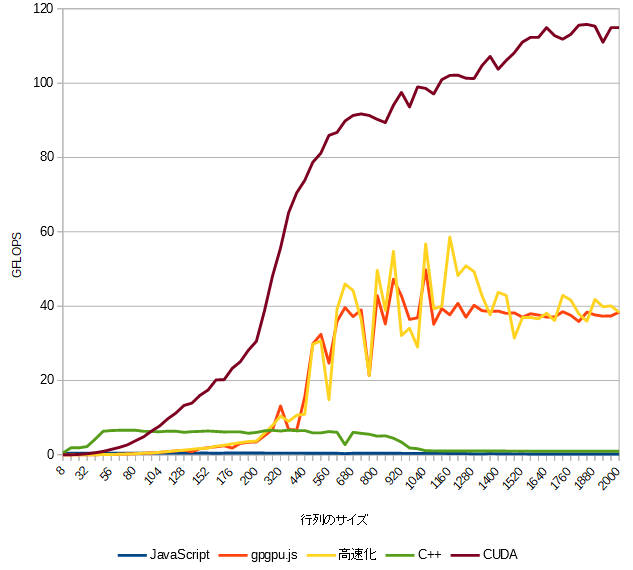
このグラフではCUDAが相変わらず速く、それにgpgpu.jsが続きます。
gpgpu.jsの高速化はそれほど効果がないように見えます。
C++は行列サイズが1000あたりから急に速度が落ちています。
2個の1000x1000のfloatの行列をかけ算するときのメモリサイズは 2 * 4 * 1000 * 1000 = 8MB です。
Core i7-6700のキャッシュメモリは8MBなのでキャッシュメモリの限界かもしれません。
C++のコードの改善¶
以下は行列の積 \(C = A \cdot B\) のC++のコードです。
#pragma omp parallel for
for (int row = 0; row < size; row++) {
for (int col = 0; col < size; col++) {
float sum = 0.0f;
for (int i = 0; i < size; i++) {
sum += A[row * size + i] * B[i * size + col];
}
C[row * size + col] = sum;
}
}
sumを計算する i のforループで B[i * size + col] を参照していますが、 i が1つカウントアップすると size だけ離れたメモリをアクセスします。
size が2000だとかなり離れた場所になります。
そこで BT をBの転置行列 \(B^T\) として以下のコードに変更してみます。
こうすると i をカウントアップしたときに BT[col * size + i] は連続したメモリ領域になります。
#pragma omp parallel for
for (int row = 0; row < size; row++) {
for (int col = 0; col < size; col++) {
float sum = 0.0f;
for (int i = 0; i < size; i++) {
sum += A[row * size + i] * BT[col * size + i];
}
C[row * size + col] = sum;
}
}
変更後のC++のグラフ¶
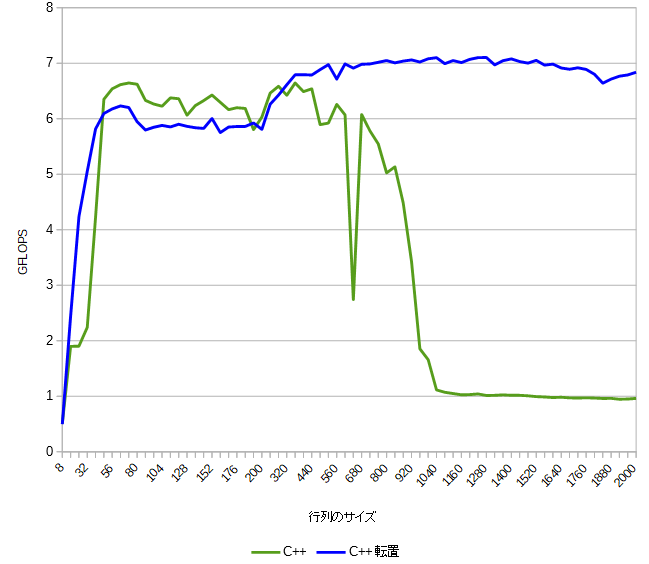
明らかに転置の効果が出ています。
C++では転置の効果が顕著なのに、gpgpu.jsでは転置の効果がないのは GeForce のキャッシュメモリが優秀で飛び飛びのメモリにアクセスしてもキャッシュメモリが対応してくれているのかもしれません。
NVIDIA以外のGPUのテスト¶
CUDAが使えないNVIDIA以外のGPUのテストをしてみます。
- OS
- Windows10 64bit
- CPU
- Core i5-6200U 2.3GHz メモリ:8GB 論理コア:4個
- GPU
- CPU内蔵 Intel HD Graphics 520 1.5GHz
NVIDIA以外のGPUのグラフ¶
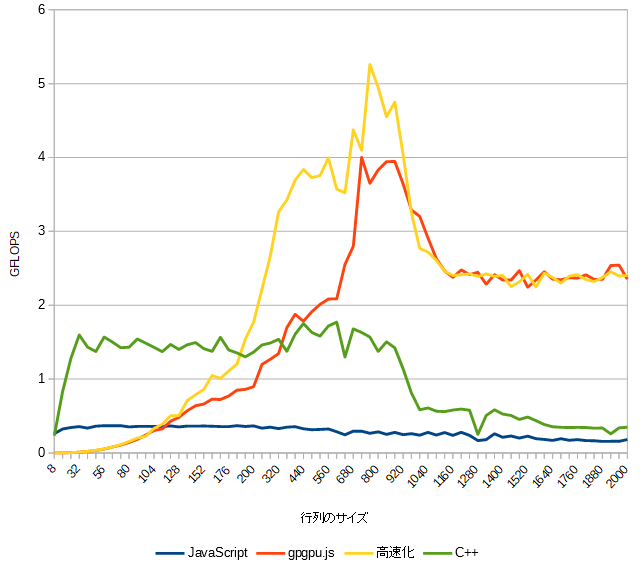
こちらではgpgpu.jsで高速化の効果が見れます。
CPU内蔵のGPUのキャッシュメモリは GeForce ほど優秀ではないからかも知れません。
C++はやはり行列のサイズが大きいと速度が落ちています。(変更前のコードでテストしています。)
まとめ¶
以下の現象が見られました。
- 大きいサイズの行列ではCUDAは最速で、gpgpu.js はCUDAに次いで速い。
- CPU内蔵のGPUではgpgpu.jsの高速化は効果があった。
- C++は行列のサイズが大きいと極端に計算速度が落ちるが、連続したメモリ領域をアクセスするように変更すると計算速度を維持できる。